
是什么
Look-Tongji-Notes[1]是由我开发的用于处理同济大学智慧录课平台中的课程录像的Agent Skill套件(根本作用是为了期末补天的时候方便一点),功能如下:
- 使用 Playwright 完成同济统一认证登录
- 列出课程(最近课程 / 全量搜索)
- 转写指定课程节次,输出字幕
SRT与纯文本TXT - 根据字幕
SRT由当前 Agent 生成"时间轴大纲"(*_timeline.txt,简体中文) - 下载指定课程节次的 slide 截图
- 由当前 Agent 基于转写文本 + slide 图片生成 Markdown 笔记
下面是这个Skill包含的9个原子化命令的列表
| 命令 | 说明 |
|---|---|
/setup | 配置凭据,检查依赖(Python、Node.js、ffmpeg、vision-support、TeX),设置工作区 |
/list | 列出课程,关键词搜索,交互式选择 |
/trans | 单节转写为 SRT + TXT;可选并行下载 slide |
/note | 从转写文本 + slide 生成学习笔记 + 时间轴大纲 |
/add | 导入补充资料(PDF、PPTX、DOCX)到课程节次 |
/wiki | 构建并本地 serve 静态课程知识库 |
/page | 将构建的课程 wiki 部署到 GitHub Pages(通过 gh CLI) |
/cheatsheet | 从课程笔记生成 A4 速查表(LaTeX 或 HTML) |
/ralphtrans | 批量转写整门课程全部节次,支持断点续传 |
怎么用
使用该Agent Skill,首先的前提条件是你要使用一个原生支持Skills[2]协议的Coding Agent
如Claude Code、Codex、Cursor、GitHub Copilot (VS Code)、Trae、CodeBuddy、Pi、GA等,此处不再赘述部署方法,互联网上有大量相关教程和广告,可以自行挑选使用;
提示
建议Agent选型:由于需要执行利于文本阅读、整理和汇总等操作的任务,不必选用太重思考的Agent(
如Codex),产出速度会比较慢且笔记内容冗长不适于突击复习,使用ClaudeCode、Pi等适用于快速迭代且有高效的上下文管理机制的Agent会有不错的效果;建议Harness选型:如果你使用自己搭建的Harness来使用此Skill,请特别注意重试机制以及可观测性的设计,必要时要做一些上下文隔离,因为该Skill在执行长线任务(如一次性转写一门课的全部节次)的过程中,难免会遇到各种阶段(下载、转写、元数据编辑等)任务失败的现象,处理这些问题是必要的,否则会极大地降低使用体验;
建议LLM选型:使用自带上下文支持1M的、低幻觉的、工具调用能力强的还有最好支持视觉的长上下文大模型(如Kimi 2.6,Qwen 3.7 Max, Mimo, DeepSeek V4 Flash)(
当然Claude系列也是很好了,只不过想必用来干这种活我不是很用得起吧)PS:对于不支持视觉的模型,在配置阶段提供了
vision-support这一选项,可以实现外挂一个视觉模型来为如DeepSeek V4 Flash等本身便宜且好用的模型辅助视觉的效果(强烈建议外挂Gemini系列模型作为视觉辅助,单论视觉能力,Gemini还是比较有性价比的选择)。
安装
推荐通过npx skills方法来安装此Skill,会被安装到~/.agents/skills目录中,支持软链接到多个Agent的Skills目录使用,比较方便快捷,如果需要更新,再复制执行一次安装即可。
npx skills install https://github.com/walkerkiller/look-tongji-notes你也可以通过Codex/Claudecode的Skill Market安装:
/plugin marketplace add https://github.com/walkerkiller/look-tongji-notes
/plugin install look-tongji-notes后续的更新以及状态管理需要自己手动执行,对应的目录也在相应Agent的配置文件目录中;
配置项目
在使用setup配置你的工作环境时,会在本地存储用.env你的学号、密码、工作目录以及外挂的视觉模型的相关信息(建议选一个单独的文件夹,后续的转写文件都会被按固定格式组织在该文件夹中,方便查询使用),还有可选的Github仓库,用于上传你的课程知识库生成Github Pages来供你阅览。
此外,wiki的前端还可设置 owner_name和site_name,会影响你的前端自定义显示的内容。(XXX的课程知识库)
配置好的工作目录下大概有这些内容:
raw/:课程原始数据与llmwiki源会话输入。wiki/:可编辑的知识库页面与课程配置。site/:python -m llmwiki build生成的静态站点。llmwiki/:从 skill 同步进来的前端与构建包。
使用流程
推荐使用下面的使用流程:
信息
本项目借鉴了Karpathy的LLM Wiki[3]设计思想,大概使用过程为
- 基础层:
/setup配置,准备环境/list让Agent通过登录验证配置、了解的课程情况 - 索引层:
/trans转写课程和/add添加材料来把课程录像以及课件等外部资料来源变成语料/note通过阅读原始的语料整理为结构化的笔记(产出一份总结的笔记和一个对于课程录像的结构化时间轴总结方便快速定位) - 应用层:
/wiki和/page分别在本地和云端把结构化的笔记呈现为一个易于人类阅读的前端网站知识库/cheatsheet通过课程的原始语料和结构化语料,整理用于开卷考试/背诵的独立清单。
ps:/ralphtrans采用hook的方式管理一次性多节课程的转录,但是由于我没有做过大批量的测试,并不清楚效果如何,你也可以直接采用对Agent描述的方式让它采用/trans一次性转写多节,一般是没有问题的。
一些个人使用经验
- “一次性”的长线任务在弱的约束下容易引起Agent偷懒的现象,如一次转写20节课然后写笔记,可能前几节还写的比较认真,后几节就写了一百多个字,建议采用你喜欢的状态管理方式(如使用Hook在每轮开始前注意强调的Prompt、开Subagent隔离上下文等等),再不济可以自己亲力亲为多轮“鞭策”Agent,确保把笔记准备为高质量的内容。
- 笔记的内容是“可迭代”的,你可以在后续丰富材料的过程中,指挥Agent更新笔记,必要时还可以做版本管理。需要注意的是前端建站采用的是
raw/sessions/里的 session markdown文件,而/note命令默认更新的是raw/<课程名>*/原始数据/*_notes.md笔记文件,它们是两套独立数据。/note命令更新了笔记文件,但 build 时只读了session文件,所以笔记更新会没有反映到 wiki 页面上。如果你的更新没有反映到前端上,可以告诉Agent这一点,使其更新session里的索引。 - 一切修复任务可以由Agent代劳:所有遇到的格式不标准引起的渲染错误、课程视频链接解析失败、课程对应名称错误、课程视频的字幕没有外挂到前端视频播放器等等,或者是你想自定义知识库的页面什么的(比如换个背景色,给前端加个密码,把图片传上图床),这些都是小Case,都可以由Agent代劳,告诉它出现的现象或者是想要达成的效果,通过简单的排查,Agent就可以帮你达成很好的效果。
- AI会出错:如果笔记中出现了不符合你的专业常识或者很离谱的内容,请务必核查,大模型出错是正常的,甚至强烈建议你做交叉验证来保证笔记内容的正确性。
- 有关字幕识别服务:当前字幕识别没有采用本地模型,本工具中使用的是必剪Bcut的接口,默认可以识别中英双语,个人使用下来精准程度还不错,如果接口暴毙,或者你有识别其他语言的需求,请考虑部署本地的ASR语音模型,或者换用更好的云端接口(魔搭上就有不少可以选用),告诉Agent你采用的方式,让它帮你替换。
- Windows:Windows系统在重启前没有良好的临时文件回收机制,如果一次性转写多节课程,会下载大量的临时课程视频资源,请主动清理临时文件避免你的存储空间告急。
- 使用成品Agent的定时任务,你可以轻易的开发出一些定时监控课程录像并为你产生最新笔记发送到你的邮箱或者自更新知识库的功能,总之,在万能的Agent的大手笔之下,一切使用效果由你的想象力定夺了。
个人课程Wiki页面预览
- 首页
- 日志页
- 课程页
- 具体节次页
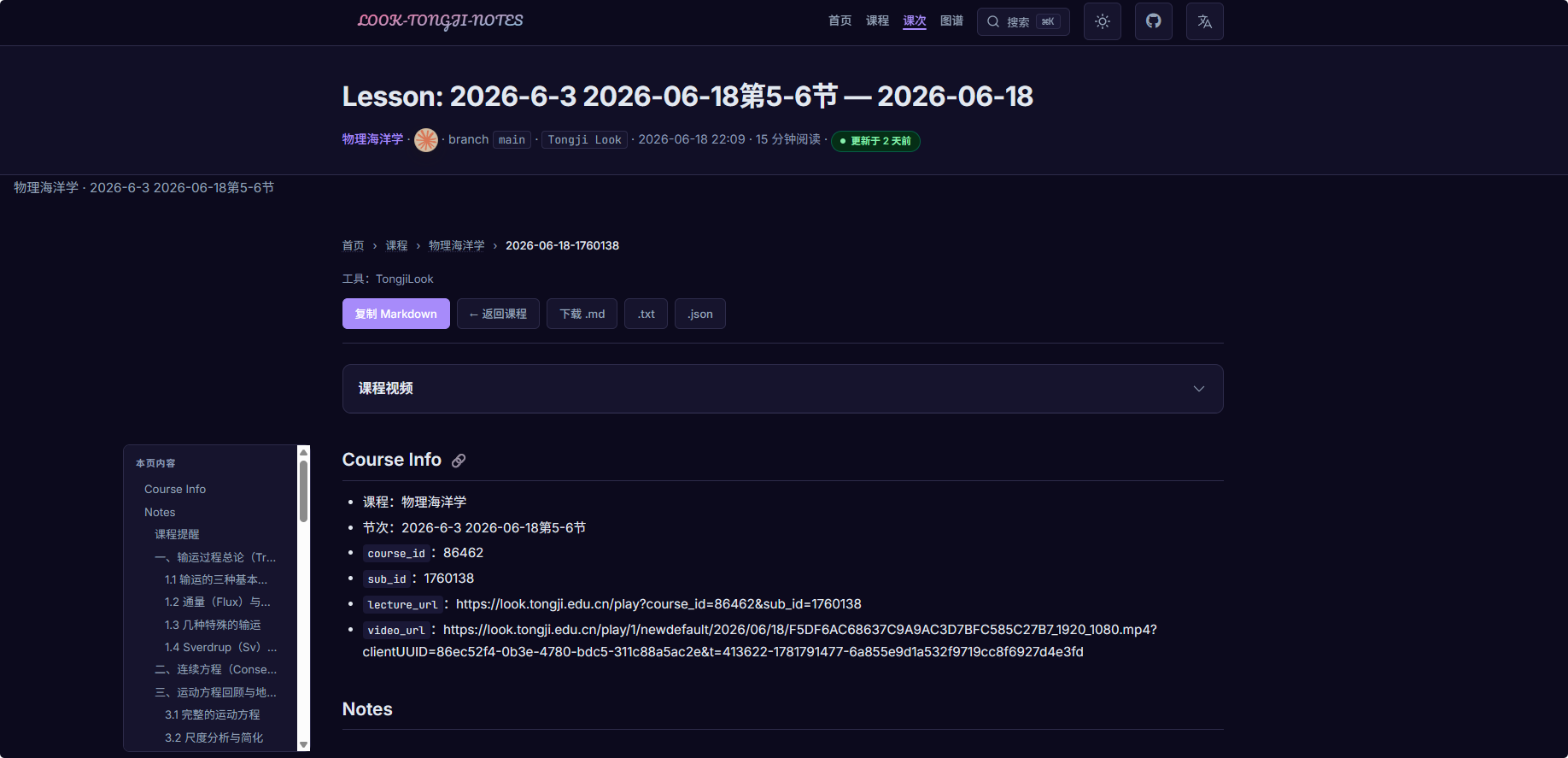
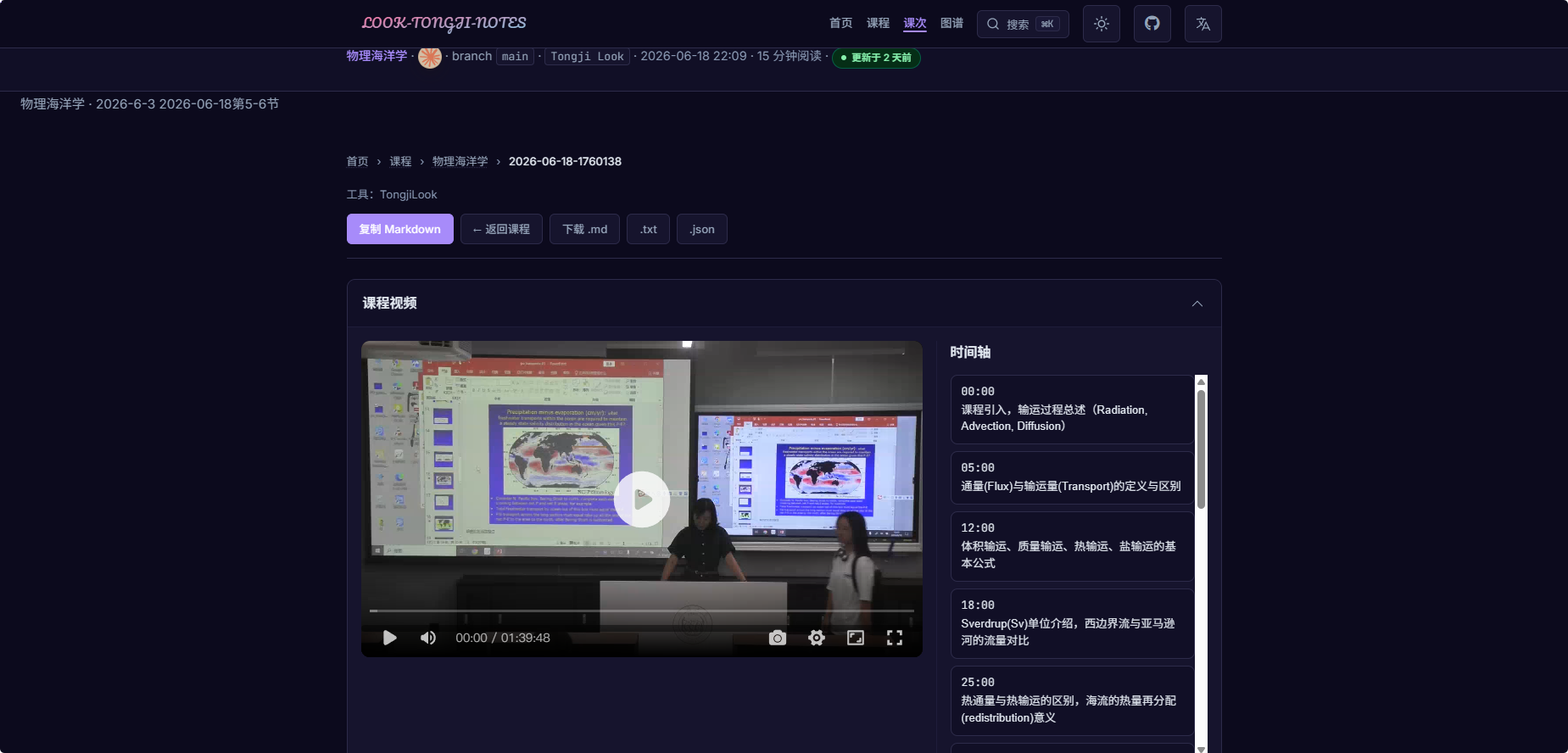
ps:视频播放器使用了
artplayer,支持倍速、字幕样式调节、帧截图等操作
- 图谱页
这个连接关系是需要让Agent处理的,此设计还在初期阶段,如果需求不大不建议现在使用
后记
设计并使用该Skill借鉴了不少开源项目,在项目README中我也标注了来源,在此再次致敬。也感谢其他几位同学的共建,这应该算是第一个由我从头做起后有其他人来贡献代码的仓库了。后续也欢迎更多同学在批判性使用的前提下来参与共建,使这个工具变得更好。如果还有什么使用方面的问题,完全可以丢给Agent这个仓库的链接,让它帮你分析问题如何产生又如何解决,亦或是让Agent教你从头开始使用这个Skill。
燃烧Token就能轻易获取到知识的年代,我们是何其幸运又何其不幸呢。
(真希望LLM、Agent什么的从未存在过,这是违心的话吗,这可以是违心的话吗)



")